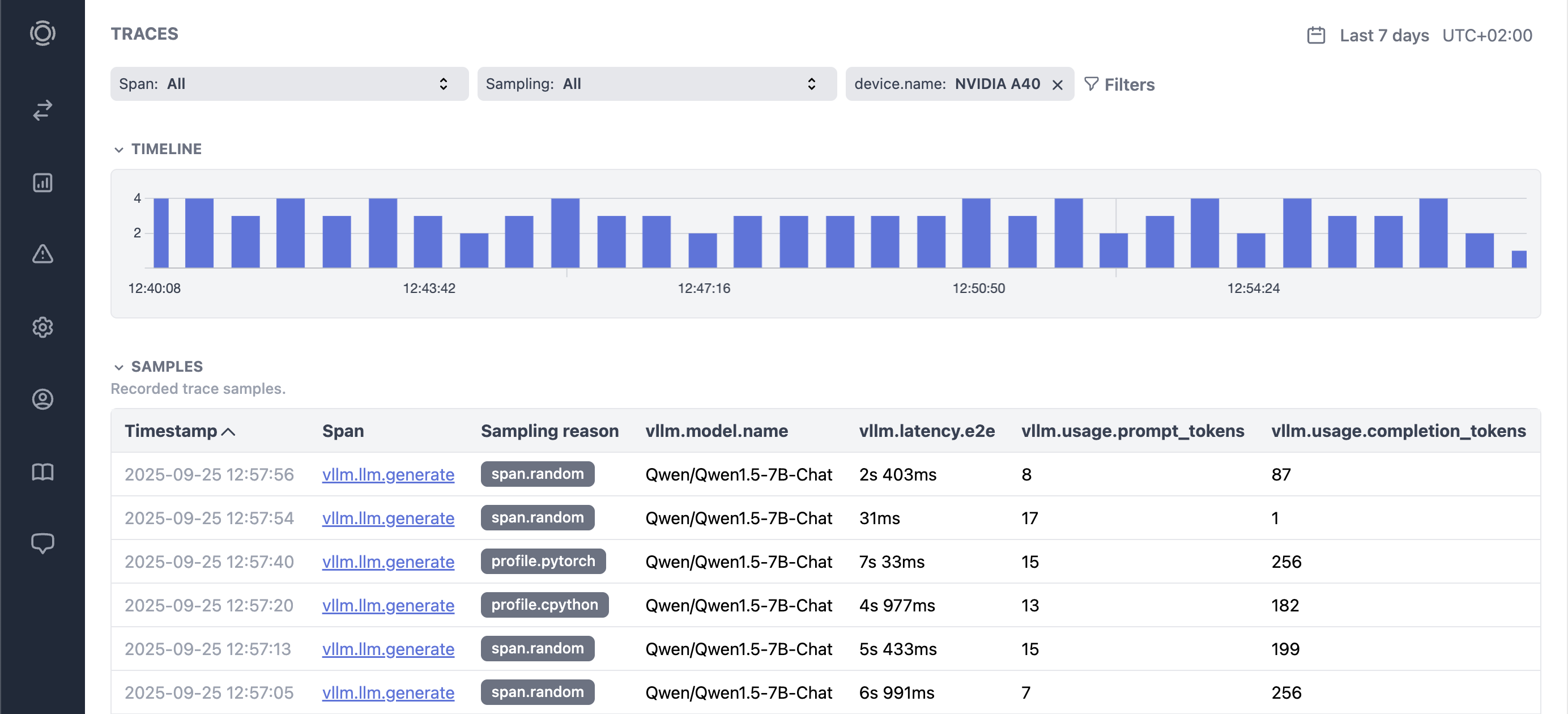
Inference Observability
Trace LLM generations, profile CUDA operations, track 100+ GPU and inference metrics, monitor XID errors and code exceptions — all in one place, all automatically.
NVIDIA PyTorch
PyTorch Hugging Face
Hugging Face vLLM
vLLM
PyTorchHugging FacevLLMInference tracing and profiling
Trace and profile LLM generations, communication, CUDA kernels, batching, and more.
GPU and server monitoring
Monitor inference performance, CPU/GPU utilization, memory usage, and server metrics.
Error monitoring
Track and get alerst on errors and exceptions - with contextual data, stack traces, and triggering conditions.
Performance analysis
Compare performance across models, versions, hardware setups, and optimization configurations.